Spark SQL 实时数据分析案例及源码
什么是SPARK SQL?
官方有详细的说明,请参考:http://spark.apache.org/docs/latest/sql-programming-guide.html
什么是JDBC?
JDBC(Java Data Base Connectivity, java数据库连接)是一种用于执行SQL语句的Java API,可以为多种关系数据库提供统一访问,它由一组用Java语言编写的类和接口组成。JDBC提供了一种基准,据此可以构建更高级的工具和接口,使数据库开发人员能够编写数据库应用程序,同时,JDBC也是个商标名。
为什么是ThriftServer?
SPARK 将数据表注册到HiveContext,再启动 ThriftServer 提供JDBC服务器,JDBC客户端连接ThriftServer,完美结合,外部可以访问spark内部(内存)数据。
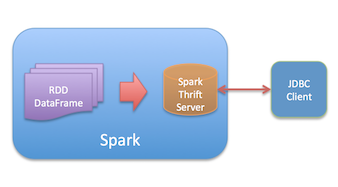
当然,也可以参考之前的博客【SPARK】Spark写入Parquet,暴露JDBC引擎,实现准实时SQL查询 来了解数据处理相关内容。
上源码才是王道
1、Spark 1.6需要开启SingleSession,否则看不见TempTable。
sparkConf.set("spark.sql.hive.thriftServer.singleSession", "true")2、初始化 HiveContext,注意是HiveContext不是SqlConctext。
val hiveContext = new HiveContext(sc)3、创建DataFrame
val df = hiveContext.createDataFrame(line) //创建DataFrame4、注册临时表
df.registerTempTable("logs")
top10SrcIp24Hour.registerTempTable("top10")5、启动ThriftServer
hiveContext.setConf("hive.server2.thrift.port", "19898") //自定义端口
HiveThriftServer2.startWithContext(hiveContext)JDBC连接,看效果
启动spark自带的JDBC 客户端 beeline,连接ThriftServer,查询表。
$SPARK_HOME/bin/beeline
Beeline version 1.6.1 by Apache Hive
beeline> !connect jdbc:hive2://localhost:19898
Connecting to jdbc:hive2://localhost:19898
Enter username for jdbc:hive2://localhost:19898:
Enter password for jdbc:hive2://localhost:19898:
Connected to: Spark SQL (version 1.6.1)
Driver: Spark Project Core (version 1.6.1)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://localhost:19898> show tables;
+------------+--------------+--+
| tableName | isTemporary |
+------------+--------------+--+
| top10 | true |
| logs | true |
+------------+--------------+--+
2 rows selected (0.184 seconds)
0: jdbc:hive2://localhost:19898> select * from top10;
+------------------+--------+--+
| ipAddress | count |
+------------------+--------+--+
| 223.166.68.96 | 87 |
| 125.39.160.25 | 22 |
| 199.101.117.71 | 17 |
| 101.226.66.180 | 10 |
| 116.53.227.116 | 4 |
| 110.173.17.149 | 1 |
| 36.231.22.250 | 1 |
| 42.120.160.30 | 1 |
| 180.153.185.118 | 1 |
+------------------+--------+--+
9 rows selected (2.233 seconds)
0: jdbc:hive2://localhost:19898> select count(*) from logs;
+------+--+
| _c0 |
+------+--+
| 144 |
+------+--+
1 row selected (2.602 seconds)
0: jdbc:hive2://localhost:19898> 看,这些数据都来自Spark内存,是不是很神奇?