Cosine similarity 余弦相似性原理及其应用
什么是余弦相似性
余弦相似性通过测量两个向量的夹角的余弦值来度量它们之间的相似性。0度角的余弦值是1,而其他任何角度的余弦值都不大于1;并且其最小值是-1。从而两个向量之间的角度的余弦值确定两个向量是否大致指向相同的方向。两个向量有相同的指向时,余弦相似度的值为1;两个向量夹角为90°时,余弦相似度的值为0;两个向量指向完全相反的方向时,余弦相似度的值为-1。这结果是与向量的长度无关的,仅仅与向量的指向方向相关。余弦相似度通常用于正空间,因此给出的值为0到1之间。
注意这上下界对任何维度的向量空间中都适用,而且余弦相似性最常用于高维正空间。例如在信息检索中,每个词项被赋予不同的维度,而一个文档由一个向量表示,其各个维度上的值对应于该词项在文档中出现的频率。余弦相似度因此可以给出两篇文档在其主题方面的相似度。
另外,它通常用于文本挖掘中的文件比较。此外,在数据挖掘领域中,会用到它来度量集群内部的凝聚力。
定义
两个向量间的余弦值可以通过使用欧几里得点积公式推导:

给定两个属性向量, A 和B,其余弦相似性θ由点积和向量长度给出,如下所示:
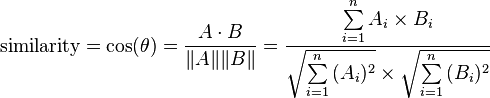
这里的A_i和B_i分别代表向量A和B的各分量。
给出的相似性范围从-1到1:-1意味着两个向量指向的方向正好截然相反,1表示它们的指向是完全相同的,0通常表示它们之间是独立的,而在这之间的值则表示中间的相似性或相异性。
对于文本匹配,属性向量A 和B 通常是文档中的词频向量。余弦相似性,可以被看作是在比较过程中把文件长度正规化的方法。
在信息检索的情况下,由于一个词的频率(TF-IDF权)不能为负数,所以这两个文档的余弦相似性范围从0到1。并且,两个词的频率向量之间的角度不能大于90°。
角相似性
“余弦相似性”一词有时也被用来表示另一个系数,尽管最常见的是像上述定义那样的。透过使用相同计算方式得到的相似性,向量之间的规范化角度可以作为一个范围在[0,1]上的有界相似性函数,从上述定义的相似性计算如下:
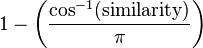
在这一公式中,向量系数可能是正,也可能是负。
或者,用以下式子计算
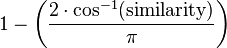
而在这一式子中,向量系数总是正的。
虽然“余弦相似性”一词有时会用来表示这个角距离,但实际上很少这样说,因为角度的余弦值只是作为一种计算角度的简便方法而被用到,本身并不是意思的一部分。角相似系数的优点是,当作为一个差异系数(从1减去它)时,在不为第一种意义的情况下,产生的函数是一个严格距离度量。然而,对于大多数的用途,这不是一个重要的性质。若对于某些情况下,只有一组向量之间的相似性或距离的相对顺序是重要的,那么不管是使用哪个函数,所得出的顺序都是一样的。
与“Tanimoto”系数的混淆
有时,余弦相似性会跟一种特殊形式的、有着类似代数形式的相似系数相混淆:

事实上,这个代数形式是首先被Tanimoto定义,作为在所比较集合由位元向量表示时计算其Jaccard系数的方法。虽然这公式也可以扩展到向量,它具有和余弦相似性颇为不同的性质,并且除了形式相似外便没有什么关系。
Ochiai系数
这个系数在生物学中也叫Ochiai系数,或Ochiai-Barkman系数:
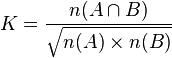
这里A和B是集合,n(A)是A的元素个数。如果集合由位元向量所代表,那么可看到落和系数跟余弦相似性是等同的。
应用
我们还希望找到与原文章相似的其他文章。比如,"Google新闻"在主新闻下方,还提供多条相似的新闻。为了找出相似的文章,需要用到"余弦相似性"(cosine similiarity)。下面,我举一个例子来说明,什么是"余弦相似性"。
简单起见,我们来看看下面的句子:
A:我喜欢看电视,不喜欢看电影。
B:我不喜欢看电视,也不喜欢看电影。
请问怎样才能计算上面两句话的相似程度?
基本思路是:如果这两句话的用词越相似,它们的内容就应该越相似。因此,可以从词频入手,计算它们的相似程度。
第一步:分词
A:我/喜欢/看/电视,不/喜欢/看/电影。
B:我/不/喜欢/看/电视,也/不/喜欢/看/电影。第二步:列出所有的词、字
我,喜欢,看,电视,电影,不,也第三步:计算词频
A:我 1,喜欢 2,看 2,电视 1,电影 1,不 1,也 0。
B:我 1,喜欢 2,看 2,电视 1,电影 1,不 2,也 1。第四步:描述词频向量
A:[1, 2, 2, 1, 1, 1, 0]
B:[1, 2, 2, 1, 1, 2, 1]到这里,问题就变成了如何计算这两个向量的相似程度。
我们可以把它们想象成空间中的两条线段,都是从原点([0, 0, ...])出发,指向不同的方向。两条线段之间形成一个夹角,如果夹角为0度,意味着方向相同、线段重合;如果夹角为90度,意味着形成直角,方向完全不相似;如果夹角为180度,意味着方向正好相反。因此,我们可以通过夹角的大小,来判断向量的相似程度。夹角越小,就代表越相似。
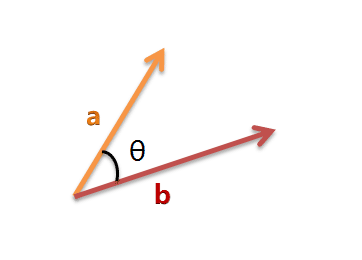
以二维空间为例,上图的a和b是两个向量,我们要计算它们的夹角θ。余弦定理告诉我们,可以用下面的公式求得:
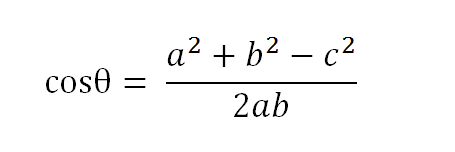
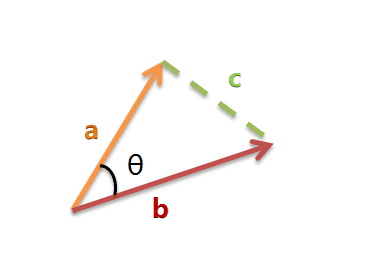
假定a向量是[x1, y1],b向量是[x2, y2],那么可以将余弦定理改写成下面的形式:
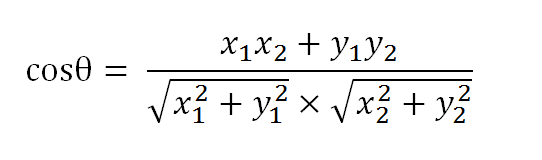

数学家已经证明,余弦的这种计算方法对n维向量也成立。假定A和B是两个n维向量,A是 [A1, A2, ..., An] ,B是 [B1, B2, ..., Bn] ,则A与B的夹角θ的余弦等于:

使用这个公式,我们就可以得到,句子A与句子B的夹角的余弦。

余弦值越接近1,就表明夹角越接近0度,也就是两个向量越相似,这就叫"余弦相似性"。所以,上面的句子A和句子B是很相似的,事实上它们的夹角大约为20.3度。
由此,我们就得到了"找出相似文章"的一种算法:
(1)使用TF-IDF算法,找出两篇文章的关键词;
(2)每篇文章各取出若干个关键词(比如20个),合并成一个集合,计算每篇文章对于这个集合中的词的词频(为了避免文章长度的差异,可以使用相对词频);
(3)生成两篇文章各自的词频向量;
(4)计算两个向量的余弦相似度,值越大就表示越相似。"余弦相似度"是一种非常有用的算法,只要是计算两个向量的相似程度,都可以采用它。