Zeppelin JDBC 数据可视化(WEB方式)
前面有篇文章,介绍Zeppelin MySQL Interpreter 的功能,可以访问MySQL数据库,并实现数据可视化,今天,有更好更方便的方式来访问MySQL,那就是 Zeppelin JDBC 方式,当然,你得有Spark和scala编程知识。虽然是一大挑战,但是值得你付出。不行咱们来看……
理解概念
-
Zeppelin: Apache Zeppelin 是一个让交互式数据分析变得可行的基于网页的notebook。Zeppelin提供了数据可视化的框架。Zeppelin提供了数据分析、数据可视化等功能。使用Spark作为数据获取方式,更加方便可靠。
-
可视化: 可视化(Visualization)是利用计算机图形学和图像处理技术,将数据转换成图形或图像在屏幕上显示出来,并进行交互处理的理论、方法和技术。它涉及到计算机图形学、图像处理、计算机视觉、计算机辅助设计等多个领域,成为研究数据表示、数据处理、决策分析等一系列问题的综合技术。目前正在飞速发展的虚拟现实技术也是以图形图像的可视化技术为依托的。
-
SPARK: Spark是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用并行框架,Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
-
JDBC: JDBC(Java Data Base Connectivity,java数据库连接)是一种用于执行SQL语句的Java API,可以为多种关系数据库提供统一访问,它由一组用Java语言编写的类和接口组成。JDBC提供了一种基准,据此可以构建更高级的工具和接口,使数据库开发人员能够编写数据库应用程序.
需求描述
其实,对于很多时候,大家的可视化需求都差不多,最容易让人体验到的是:WEB展示方式,JDBC连接方便(Oracle, MySQL, MSSQL, PostgreSQL等),SQL语句,图表化,最好可以随时调整。对了,就是这样的需求。
实现方式
1. 推荐下载zeppelin 0.5.5版本,找一个离你最近的站点,
wget http://www.apache.org/dyn/closer.cgi/incubator/zeppelin/0.5.5-incubating/zeppelin-0.5.5-incubating-bin-all.tgz
tar -zxvf zeppelin-0.5.5-incubating-bin-all.tgz
cd zeppelin-0.5.5-incubating-bin-all下载MySQL jdbc driver,并复制到 zeppelin-0.5.5-incubating-bin-all/lib 目录下,启动zeppelin:
bin/zeppelin-daemon.sh start2. MySQL服务器需要开启zeppelin服务器的访问权限,这里不做说明;
3. 在MySQL服务器上把SQL语句跑一遍,保证SQL没有问题。
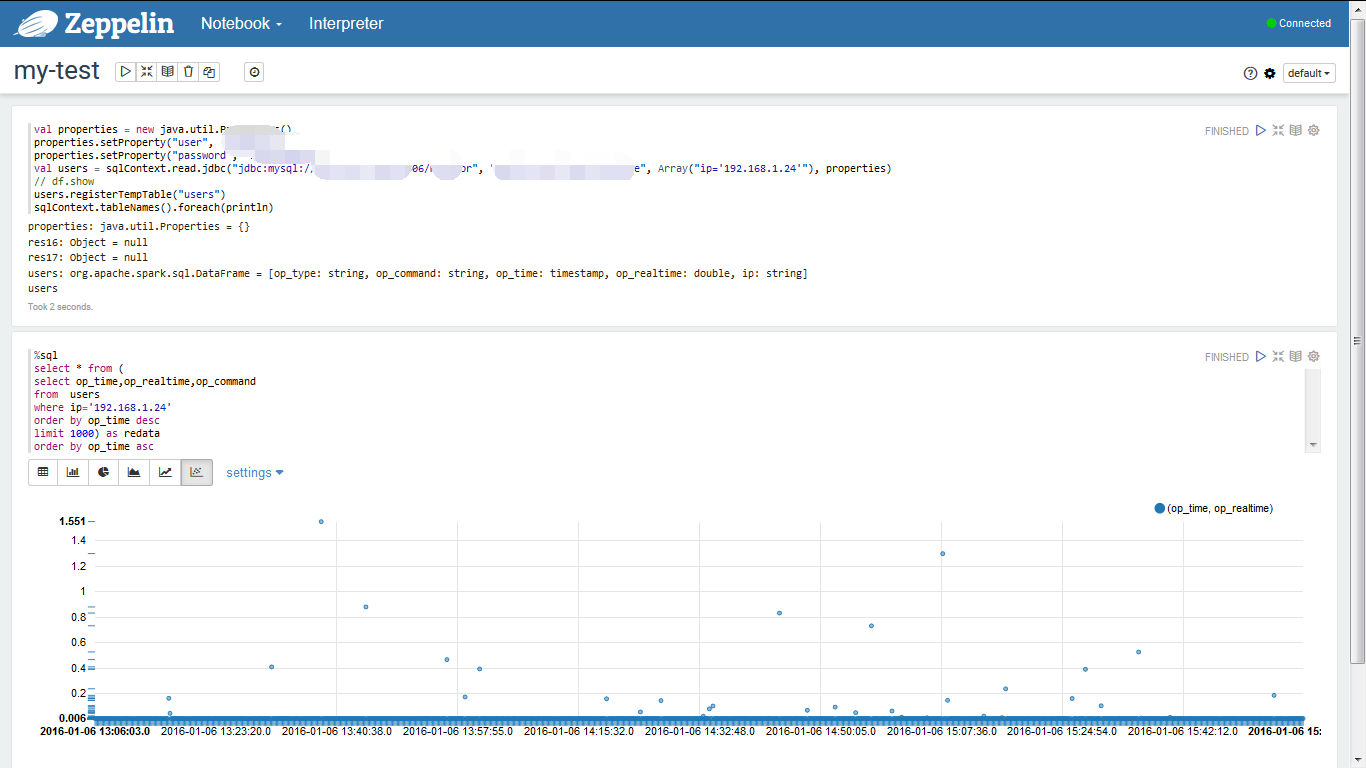
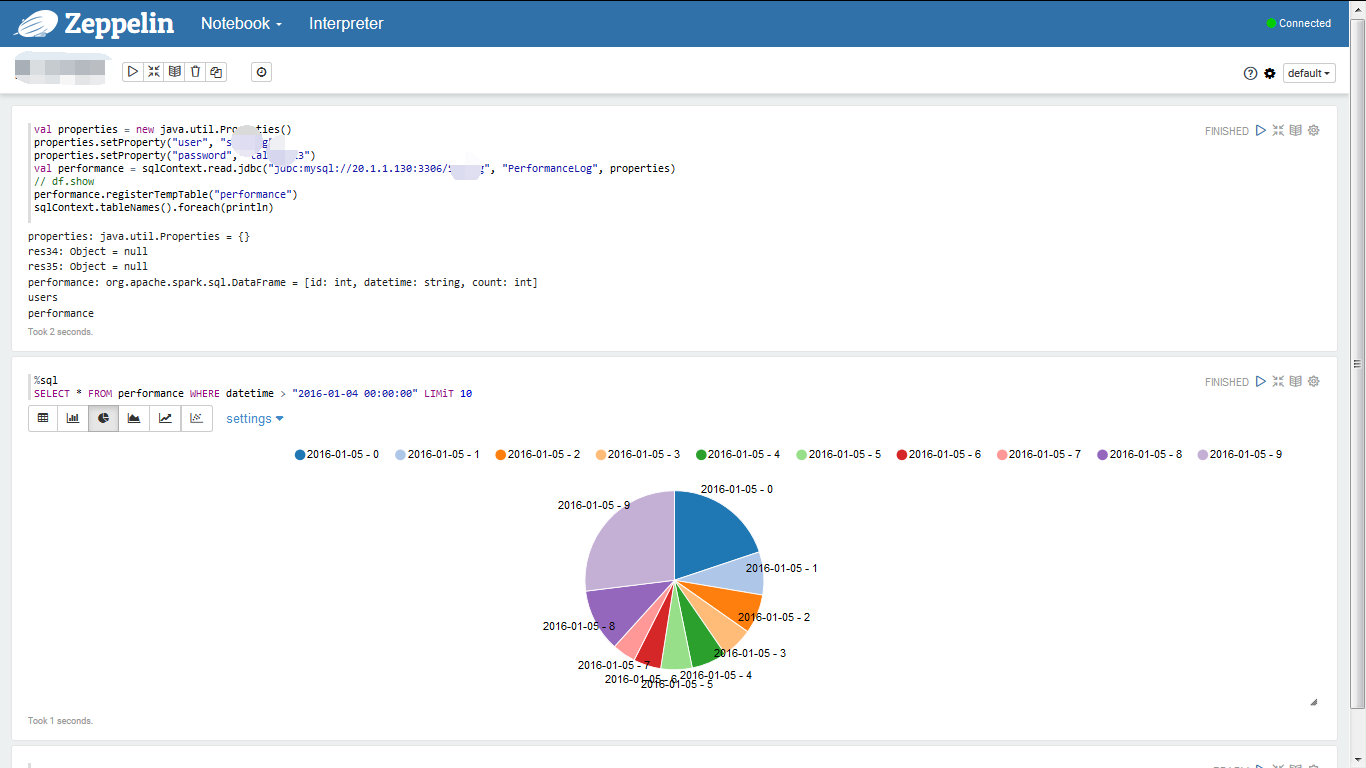
4. Zeppelin新建一个Notebook,把Spark语句放进去:
输入如下信息,点击运行Run:
// MySQL连接信息
val properties = new java.util.Properties()
properties.setProperty("user", "user")
properties.setProperty("password", "password")
// 获取数据内容
val users = sqlContext.read.jdbc("jdbc:mysql://20.1.1.130:3306/mydb", "mytable", Array("ip='192.168.1.24'"), properties)
// 创建临时查询表
users.registerTempTable("users")
// 检查临时表是否存在,实际应用中可以去除
sqlContext.tableNames().foreach(println)新建一个操作框,把SQL语句放进去,点击运行Run:
%sql
SELECT * FROM users实现效果
至于图表展示,根据自己的需求灵活定义,下面来放几张样例参考一下:
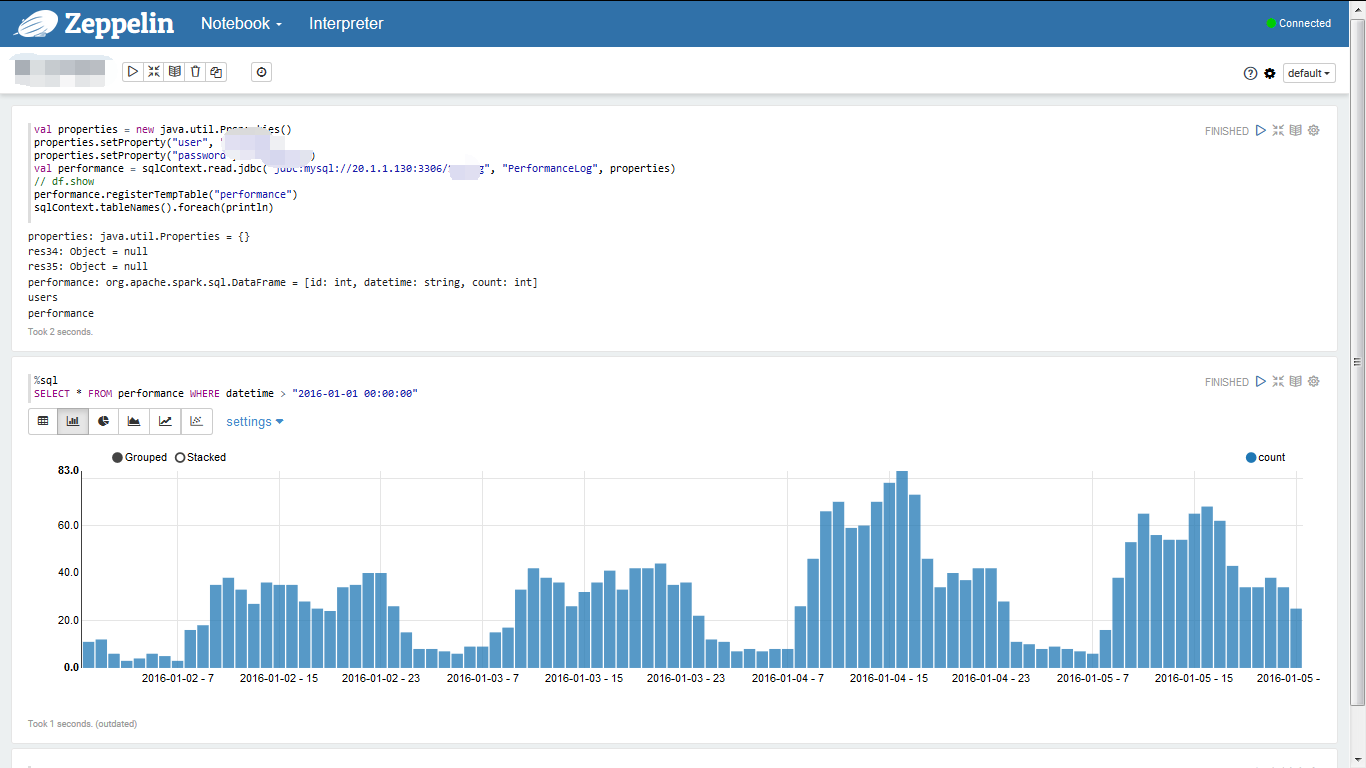
最近数据量统计——柱状图
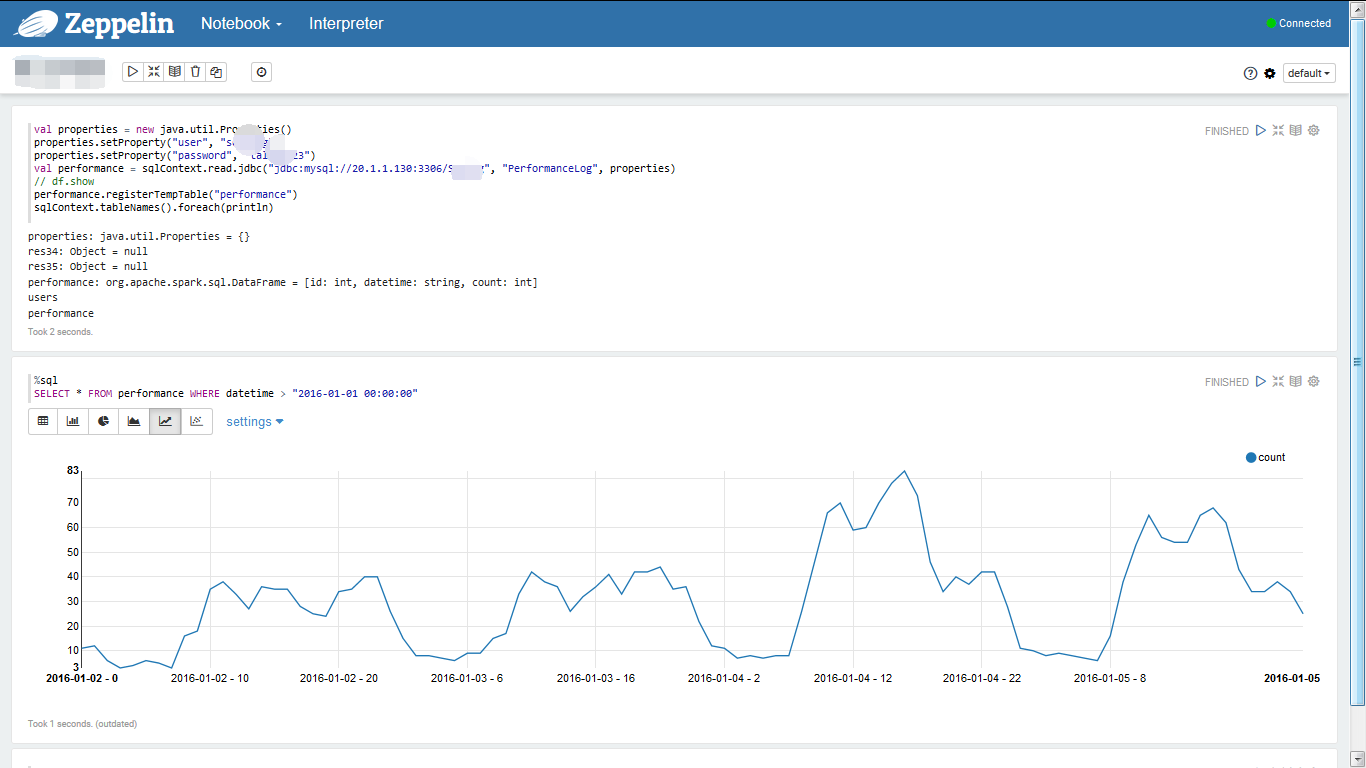
最近数据量统计——折线图
最近数据量饼图
数据库操作响应时间——散点图